
![[Antezeta Web Marketing Blog in English]](/i/en.png "Antezeta Web Marketing Blog in English")

Un motore di ricerca nuovo, Cuil, è stato lanciato per farlo diventare il prossimo Google. Cuil è stato fondato da persone con esperienza in Google, AltaVista ed IBM – il che è stato sufficiente ad ottenere l’attenzione dei mass media negli afosi giorni d’estate.

È un peccato che Cuil abbia deciso di promuovere le dimensioni del suo indice come una delle caratteristiche principali. I professionisti del settore dei motori di ricerca sanno bene che ci sono molti altri fattori che hanno un forte impatto sulla qualità dei risultati di una ricerca sul web. I documenti web indicizzati sono freschi, aggiornati? Google riesce ad indicizzare alcuni siti in pochi minuti:
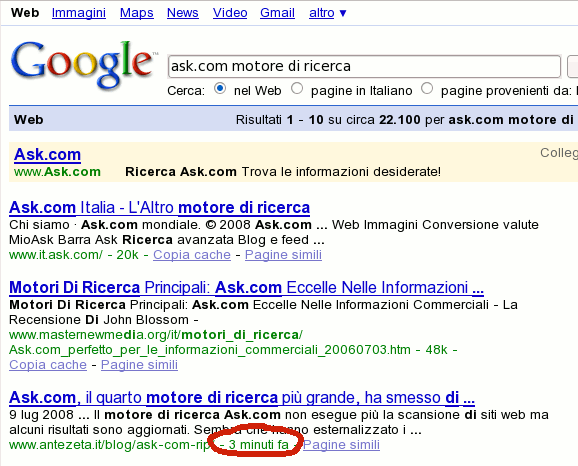
Sulla sua home page, Cuil dice “Ricerca pagine web“. Questo numero non varia da giorni; sembra che il loro indice sia più statico di quello di Google.
L’indice del motore di ricerca sa gestire i doppioni come, ad esempio, le versioni di stampa e di contenuti distribuiti su più siti? C’è un algoritmo sofisticato di classificazione per visualizzare i documenti pertinenti alle intenzioni dei navigatori web?
Diversi anni fa, dopo molti su e giù su chi potesse vantare l’indice più grande, Yahoo! e hanno deciso di passare a questioni più importanti.
Eppure, anche se un nuovo motore di ricerca capace di sfidare l’effettivo monopolio di Google viene accolto con grande favore, soprattutto perché Ask.com va in pensione con Jeeves, si deve ammettere che Cuil ha iniziato male.
Ma c’è di peggio. Cuil ha parlato di una funzionalità che “va al di là delle tecniche della ricerca di oggi basata sull’analisi di link e sulla classifica di traffico“, cioè sul raggruppamento dei relativi risultati di ricerca in cluster. Ah ecco, nulla di nuovo qui. Teoma, ora parte di Ask.com, forniva “le pagine web per argomento: le prime pagine dei risultati sono raggruppate in base ai loro argomenti“:

e Clusty continua farlo.
Se si esegue una ricerca web su Google, in pochi secondi i risultati appaiono, quasi come per magia. Il lavoro dietro le quinte necessario per arrivare a risultati mirati per una ricerca sul Web è molto più difficile di quanto non potrebbe sembrare.
Un motore di ricerca deve passare attraverso una lunga sequenza di passaggi che, in forma semplificata, consistono in tre fasi:
- Scoprire e catturare i contenuti sul web. Questo è ciò che intendiamo per scansione del Web.
- Elaborare ed indicizzare i contenuti recuperati.
- Interpretare le intenzioni di un utente web e produrre risultati pertinenti, velocemente.
I documenti basati su formati di testo, come i file HTML, in genere forniscono molte informazioni ricche con cui i motori di ricerca possono lavorare. Il loro lavoro diventa molto più oneroso quando i motori di ricerca tentano di decifrare le informazioni in immagini e file video. Nel corso degli anni Danny Sullivan ha documentato alcuni significativi esempi di quando Google ha sbagliato.
The Register, un servizio on-line per il settore IT basato nel Regno Unito (motto irriverente: Biting the hand that feeds IT, Mordendo la mano che lo nutre, dove “lo” sta anche per IT) ha individuato un esempio per il quale il grande indice Cuil non ha aiutato a fornire risultati pertinenti. Nell’esempio, le immagini in anteprima dei siti non sembrano essere correlate ai risultati della ricerca. Infatti, vediamo dei giovanotti come mamma li ha fatti, che si divertono tra di loro. Purtroppo essi sono estranei alla sostanza della ricerca, “Jonathan Grattage insegna“.
Sembra che Cuil volesse dimostrare quanto la ricerca web sia dura, o che il mio è più grande del tuo (indice, sia chiaro), solo che non sono sicuro di quale (il link probabilmente non è adatto ad un “ambiente lavorativo”; sei avvisato).
Complimenti a David Naylor (alias DaveN) e Mikkel Svendsen deMib per aver citato questo esempio sul loro podcast Strikepoint. Nell’aprile 2006 DaveN ha rilevato anche un problema con la ricerca di immagini in Google – nel caso specifico, per la bandiera del Regno Unito, una delle immagini differiva assai da quella di una bandiera, fidati.
Cuil è principalmente incentrata sulla ricerca in lingua inglese, ma fa vedere anche alcuni risultati in lingua italiana, come ad esempio nella ricerca per Blogbabel:

Il mio personale verdetto per ora: troppo Cu(i)lo stroppia. Un comunicato stampa intellettualmente disonesto non costituisce un motore di ricerca valido. Ma potrebbe essere solo il lucido specchio per le allodole che attira uno specialista che acquista aziende e che proviene da una società di private equity, uno specialista mal informato. Per una più ampia recensione su Cuil consiglio l’articolo di Danny Sullivan.
Post correlate:
- X-Robots-Tag: Ora ci sono 6 modi per tenere i contenuti dei siti web fuori dai motori di ricerca
- SEO per Multimediale Audio e Video
- Testo come Immagini: Problema SEO Ormai Superato con @font-face
- Come trarre il meglio da una brutta situazione: comunicare in modo intelligente i disservizi sul web

1 risposta finora ↓
1 Francesco Federico // 20 Aug 2008 alle 11.22.50
Il problema di Cuil è stato l’essere andato public troppo presto. I media, come hai detto tu, hanno fatto il botto e creato aspettative che il prodotto non ha saputo per nulla soddisfare.
Doveva partire molto più in sordina e sfruttare il nome della fondatrice e il suo passato solamente quando erano certi di avere il motore pronto.
Così com’è Cuil è assolutamente inutile, peraltro avendo ancora pochi utenti che cercano tutti piu o meno le stesse cose il motore semantico è molto sbilanciato e restituisce risultati spesso assurdi.
Lascia un commento
Avviso: commenti sono benvenuti nella misura in cui essi aggiungono qualcosa al discorso. Commenti senza nome e cognome e/o con toni negativi senza giustificazione razionale di una propria posizione e/o per terzi fini, corrono il rischio di essere cancellati senza pietà ad imprescindibile discrezione dell'amministratore. Ebbene sì, la vita è dura.